前言
在写 loadmd_to_wordpress 项目的时候,想着用 RC4 加密来进行前端加密
于是找 kimi 要了一个脚本
def rc4(data: str, key: str) -> str:
box = list(range(256))
key = [ord(key[i % len(key)]) for i in range(256)]
cipher, j = "", 0
for i in range(256):
j = (j + box[i] + key[i]) % 256
box[i], box[j] = box[j], box[i]
a = j = 0
for i in range(len(data)):
a = (a + 1) % 256
j = (j + box[a]) % 256
box[a], box[j] = box[j], box[a]
cipher += chr(ord(data[i]) ^ box[(box[a] + box[j]) % 256])
return cipher
由于 rc4 加密之后的密文可读性非常差,所以我打算对其进行 base64 编码之后再输出
import base64
def rc4(data: str, key: str) -> str: ...
def base64_encode(string: str) -> str:
return base64.b64encode(string.encode()).decode()
print(base64_encode(rc4('my_password', 'my_key')))
然后问题就出现了,输出的结果完全是错误的:UDhuV8OJw7rCncKFw7DCo2c=
正确的结果应该是:UDhuV8n6nYXwo2c=
正文
我一开始还以为是 kimi 给的 rc4 加密函数有问题,反复检查,一点问题都没有
怪了,难道是 base64 的问题?不完全是,由于 b64encode 接受一个 bytes,所以我们需要调用字符串的 encode 方法将其转换为 bytes
这个方法默认是用 utf-8 作编码,由于 python3 默认使用 unicode 编码,所以会发生 unicode -> utf-8 的操作
而这一操作会带来一些坑,以 chr(158) 为例
# python3 使用 unicode 作默认编码
chr(158).encode('utf-8')
# 输出 b'\xc2\x9e'
# 158 的二进制为 10011110, 那应该是 b'\x9e' 才对
UTF-8 的编码结构长度是根据某单个字符的大小来决定长度有多少,当字符 bit 数为 8 – 11 位时,会转为 110X XXXX 10XX XXXX 的形式
也就是说对于 chr(n), n>127 转换后的字符变长了,下面是 unicode 转换为 utf-8 的规则表
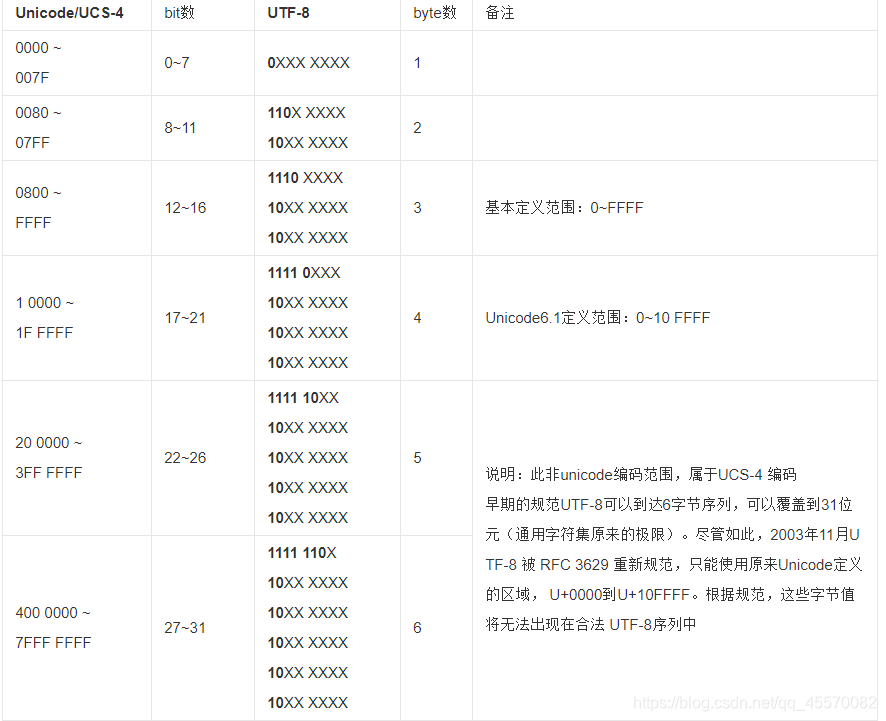
为了让 byte 转换不发生不希望的长度转换,可以选择 latin-1 作为编码规则
import base64
def rc4(data: str, key: str) -> str: ...
def base64_encode(string: str) -> str:
return base64.b64encode(string.encode('latin-1')).decode()
print(base64_encode(rc4('my_password', 'my_key')))
参考文章:python3中base64的编码问题




